Hyper-V架构与VMware ESXi的差异
微软的Hyper-V与VMware的ESXi在架构上有众多不同,然而很多虚拟化管理员并未意识到这些差异。而且很多管理员同样对Hyper-V是在主机操作系统上运行感到困惑。
有关微软Hyper-V的一个常见的误解就是安装Hyper-V需要使用Windows操作系统,Hyper-V运行在主机操作系统之上而不是直接安装在裸机上。有必要指出一旦Hyper-V角色通过Server Manager启用,hypervisor代码实际上是被配置为在Windows 内核空间内启动。运行在内核空间的组件能够直接访问硬件,这同样适用于Hyper-V。另一方面,VMware的ESXi采用了完全不同的方式,ESXi hypervisor被封装为一个单独的ISO文件,它实际上是一个Linux内核操作系统。
Hyper-V和ESXi都是 Type 1 hypervisor。 Type 1 hypervisor直接运行在硬件之上,从设计上能够将Type 1 hypervisor进一步划分为两类:microkernelized和monolithic。microkernelized设计与monolithic设计有一些细微的差异。两类设计唯一的差异就是设备驱动的位置以及控制功能。
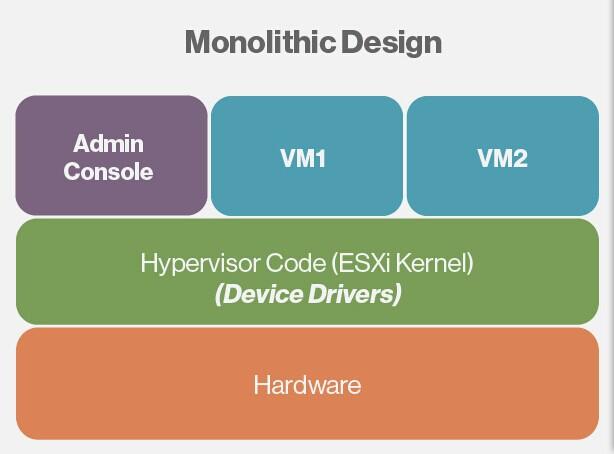
正如上图所示,在monolithic设计中,驱动被作为hypervisor的一部分包括在内。VMware ESXi使用monolithic设计实现所有的虚拟化功能,包括虚拟化设备驱动。自从首次推出虚拟化产品起,VMware一直在使用monolithic设计。由于设备驱动包含在了hypervisor中,在hypervisor代码的帮助下,运行ESXi主机之上的虚拟机能够与物理硬件直接通信,不再依赖中间设备。
微软Hyper-V 架构使用了microkernelized设计,hypervisor代码运行时没有包括设备驱动。
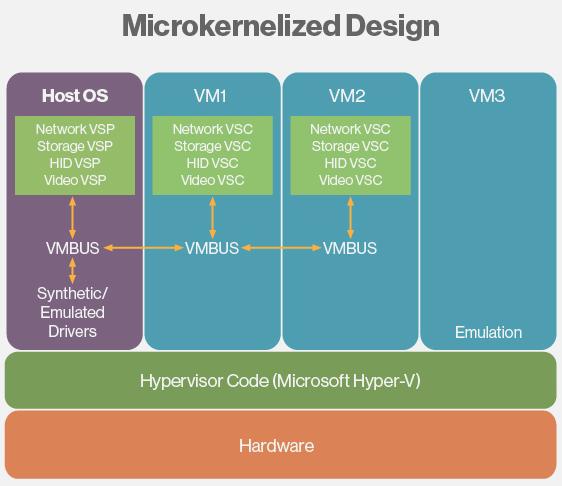
如上图所示,设备驱动安装在主机操作系统内,虚拟机访问硬件设备的请求交由操作系统处理。换句话说由主机操作系统控制对硬件的访问。有两种类型的设备驱动运行在主机操作系统内:合成的与模拟的。合成的设备驱动要比模拟的更快。只有在虚拟机上安装了Hyper-V集成服务时虚拟机才能够访问合成设备驱动。集成服务在虚拟机内实现了VMBus/VSC设计,使直接访问硬件成为了可能。例如,为访问物理网卡,运行在虚拟机内的网络VSC驱动会与运行在主机操作系统内的网络VSP驱动进行通信。网络VSC与网络VSP之间的通信发生在VMBus之上。网络VSP驱动使用虚拟合成设备驱动库直接与物理网卡通信。运行在主机操作系统内的VMBus,实际是在内核空间内运转以改进虚拟机与硬件之间的通信。如果虚拟机没有实现VMBus/VSC设计,那么只能依赖于设备模拟。
无论虚拟化厂商选择哪种设计,必须要有一个控制功能对hypervisor进行全方位的控制。控制功能有助于创建虚拟环境。微软Hyper-V架构在其Windows操作系统内实现了控制功能。换句话说,主机操作系统控制直接运行在硬件之上的hypervisor。在VMware ESXi中,控制功能在ESXi内核中实现,被Linux核心shell所控制。
很难说哪种设计更好。然而,每种设计都有各自的优势与不足之处。由于设备驱动被编码为ESXi内核的一部分,所以只能够在受支持的硬件上安装ESXi。而微软Hyper-V架构不存在这种限制,能够在任何硬件上运行hypervisor代码。这降低了维护设备驱动库的开销。使用microkernelized设计的另一个优势在于不需要在每台虚拟机上安装单个设备驱动。毫无疑问ESXi也部署了直接访问硬件的虚拟化组件,但你无法增加其他角色或服务。尽管不建议在hypervisor上安装任何其他角色及功能,但运行Hyper-V的主机还可以被配置为具有其他角色,比如DNS以及故障转移集群。
Article From:http://virtual.51cto.com/art/201411/456441.htm
Hyper-V VSP/VSC和VMBUS设计
在服务器/客户机网络应程序用中,有两个部分协同运行,以实现网络通信:服务器端组件和客户端组件。服务器端组件总是进行侦听,为客户端组件提供网络服务。
另一方面,客户端组件总是向服务器端组件请求服务。比如说,在Windows操作系统中,RPC服务器充当RPC客户机的侦听器。就微软Exchange Server而言,CAS充当服务器端组件,侦听来自Outlook邮件客户端的网络流量。
同样,Hyper-V实施了分别名为VSP和VSC的服务器端组件和客户端组件。VSP代表虚拟化服务提供者,而VSC代表虚拟化服务客户机。结合稍后讨论的VMBUS,VSP组件和VSC组件就能提升在Hyper-V上运行的虚拟机的整体性能。
在虚拟机里面运行的操作系统不知道它是在使用物理层还是在使用虚拟机与硬件设备进行通信。在虚拟环境中,操作系统组件使用原生驱动程序,发送硬件访问请求,但是请求由虚拟层负责接收。
在访问硬件设备的请求得到处理之前,这类请求被虚拟层截获。这种截获机制有时又叫设备仿真(device emulation)。由于这些被截获的调用由设备仿真组件加以处理,这总是在虚拟机与硬件设备之间带来了额外的一层通信。
为了避免额外的这层通信,微软为在Hyper-V上运行的虚拟机提供了一套组件,名为“集成服务”(Integration Services)。VMware则为在ESX Server上运行的虚拟机提供了“VMware工具”。本文将只探讨Hyper-V的集成服务组件。
虽然这一套集成服务还提供了其他服务,但VSP和VSC是微软Hyper-V虚拟化架构中大幅提升虚拟机性能的主要组件。这两个组件有助于确保子分区(虚拟机)与父分区(Hyper-V服务器)之间实现顺畅、可靠的通信。VSP总是在父分区里面运行,而VSC总是在子分区里面运行。
Hyper-V里面有四个VSP,另外四个VSC在多个子分区里面运行,如下图所示:
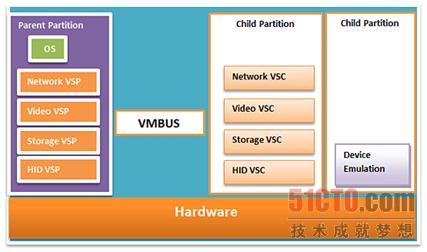
采用VSP/VSC设计的子分区
VSP(网络、视频、存储和人机接口设备)总是在父分区里面运行,而相应的VSC总是在子分区里面运行。VSP和相应的VSC都可以使用一种名为VMBUS的沟通渠道,与对方进行通信,如上图所示。
VMBUS是一种特殊的协议,旨在实现VSC与在父分区里面运行的VSP进行通信。这个组件起到了重要的作用,可以避免产生任何额外的通信层。
只有四个VSP在父分区里面的Hyper-V服务器上运行,但是可能有多个VSC在同一个Hyper-V服务器上运行,作为子分区的一部分。VSP是多线种组件,作为VMMS.exe的一部分而运行,可以同时处理多个VSC请求。
你将集成服务组件安装到虚拟机中后,下列驱动程序被安装,以改善虚拟机与父分区之间的通信:
·如果是显示屏适配器,C:\Windows\System32\VMBusVideoD.dll和C:\Windows\System32\Drivers\VMBusVideoM.Sys
·如果是人机接口设备,C:\Windows\System32\Drivers\hidusb.sys和C:\Windows\System32\Drivers\VMBusHID.SYS
·如果是网络适配器,C:\Windows\System32\Drivers\NetVSC60.sys
·如果是存储控制器,C:\Windows\System32\Drivers\StorVSC.sys
除了上面提到的几个驱动程序外,还添加了一个VMBUS设备。它使用位于C:\Windows\System32\Drivers文件夹中的VMBUS.sys驱动程序。
VSC驱动程序与装入到虚拟机中的VMBUS.sys驱动程序进行通信。VMBUS.sys则与在Hyper-V父分区里面运行的VMBUS.sys进行通信,Hyper-V父分区进而与在父分区里面运行的相应VSP进行通信,以便实现直接通信,避免了与设备仿真层进行通信。
为了证实虚拟机使用VSP/VSC设计,与父分区成功实现了通信,你可以看一下虚拟机中的设备管理器,如下面这个屏幕截图所示:
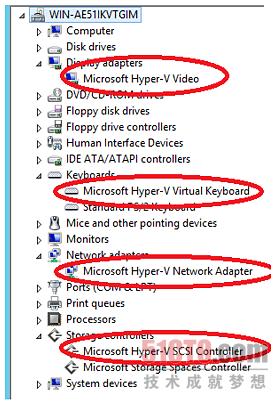
如果相应的VSC在虚拟机上正常运行,你会看到代表视频VSC的“Microsoft Hyper-V Video”、代表人机接口设备VSC的“Microsoft Hyper-V Virtual Keyboard”、代表网络VSC的“Microsoft Hyper-V Network Adapter”以及代表存储VSC的“Microsoft Hyper-V SCSI Controller”,如上图所示。
如果这些驱动程序受到了破坏,或没有出现在虚拟机中,虚拟机通信总是会使用设备仿真加以实现。
在TechED北美大会上与Windows Server 2012 R2一同宣布的第二代虚拟机中,VMBUS和VSP/VSC设计始终处于启用状态。你没法将其关闭――也没有理由将其关闭,因为它改进了虚拟机的通信。8月份我们刊发了一篇文章(http://www.serverwatch.com/server-tutorials/hyper-v-2012-r2-pros-and-cons-of-generation-1-vs.-generation-2-vms.html),专门介绍第一代虚拟机和第二代虚拟机。你可以参阅此文,进一步了解第二代虚拟机。
不采用VSP/VSC设计的子分区
上图中的第二个子分区并不实现VSC功能。可能是由于集成服务组件没有被安装,也可能是操作系统不受Hyper-V的支持。第二个子分区总是依赖设备仿真。它总是使用仿真设备驱动程序,与父分区进行通信,这会拖累虚拟机的整体性能。
结束语
通过本文,我们了解了Hyper-V的VSP组件和VSC组件在改进虚拟机与父分区之间的通信方面如何发挥了重要作用。我们还了解了这些组件作为安装在虚拟机中的集成服务的一部分而可用。要是没有VSP/VSC组件,虚拟机操作系统就会使用操作系统提供的驱动程序进行通信,这会导致虚拟机的性能出现下降。
http://www.serverwatch.com/server-tutorials/understanding-hyper-v-vspvsc-and-vmbus-design.html
设计模式六大原则
定义:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责。
问题由来:类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
解决方案:遵循单一职责原则。分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
说到单一职责原则,很多人都会不屑一顾。因为它太简单了。稍有经验的程序员即使从来没有读过设计模式、从来没有听说过单一职责原则,在设计软件时也会自觉的遵守这一重要原则,因为这是常识。在软件编程中,谁也不希望因为修改了一个功能导致其他的功能发生故障。而避免出现这一问题的方法便是遵循单一职责原则。虽然单一职责原则如此简单,并且被认为是常识,但是即便是经验丰富的程序员写出的程序,也会有违背这一原则的代码存在。为什么会出现这种现象呢?因为有职责扩散。所谓职责扩散,就是因为某种原因,职责P被分化为粒度更细的职责P1和P2。
比如:类T只负责一个职责P,这样设计是符合单一职责原则的。后来由于某种原因,也许是需求变更了,也许是程序的设计者境界提高了,需要将职责P细分为粒度更细的职责P1,P2,这时如果要使程序遵循单一职责原则,需要将类T也分解为两个类T1和T2,分别负责P1、P2两个职责。但是在程序已经写好的情况下,这样做简直太费时间了。所以,简单的修改类T,用它来负责两个职责是一个比较不错的选择,虽然这样做有悖于单一职责原则。(这样做的风险在于职责扩散的不确定性,因为我们不会想到这个职责P,在未来可能会扩散为P1,P2,P3,P4……Pn。所以记住,在职责扩散到我们无法控制的程度之前,立刻对代码进行重构。)
举例说明,用一个类描述动物呼吸这个场景:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
}
}
|
运行结果:
牛呼吸空气
羊呼吸空气
猪呼吸空气
程序上线后,发现问题了,并不是所有的动物都呼吸空气的,比如鱼就是呼吸水的。修改时如果遵循单一职责原则,需要将Animal类细分为陆生动物类Terrestrial,水生动物Aquatic,代码如下:
class Terrestrial{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
}
class Aquatic{
public void breathe(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Terrestrial terrestrial = new Terrestrial();
terrestrial.breathe("牛");
terrestrial.breathe("羊");
terrestrial.breathe("猪");
Aquatic aquatic = new Aquatic();
aquatic.breathe("鱼");
}
}
|
运行结果:
牛呼吸空气
羊呼吸空气
猪呼吸空气
鱼呼吸水
我们会发现如果这样修改花销是很大的,除了将原来的类分解之外,还需要修改客户端。而直接修改类Animal来达成目的虽然违背了单一职责原则,但花销却小的多,代码如下:
class Animal{
public void breathe(String animal){
if("鱼".equals(animal)){
System.out.println(animal+"呼吸水");
}else{
System.out.println(animal+"呼吸空气");
}
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe("鱼");
}
}
|
可以看到,这种修改方式要简单的多。但是却存在着隐患:有一天需要将鱼分为呼吸淡水的鱼和呼吸海水的鱼,则又需要修改Animal类的breathe方法,而对原有代码的修改会对调用“猪”“牛”“羊”等相关功能带来风险,也许某一天你会发现程序运行的结果变为“牛呼吸水”了。这种修改方式直接在代码级别上违背了单一职责原则,虽然修改起来最简单,但隐患却是最大的。还有一种修改方式:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
public void breathe2(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe2("鱼");
}
}
|
可以看到,这种修改方式没有改动原来的方法,而是在类中新加了一个方法,这样虽然也违背了单一职责原则,但在方法级别上却是符合单一职责原则的,因为它并没有动原来方法的代码。这三种方式各有优缺点,那么在实际编程中,采用哪一中呢?其实这真的比较难说,需要根据实际情况来确定。我的原则是:只有逻辑足够简单,才可以在代码级别上违反单一职责原则;只有类中方法数量足够少,才可以在方法级别上违反单一职责原则;
例如本文所举的这个例子,它太简单了,它只有一个方法,所以,无论是在代码级别上违反单一职责原则,还是在方法级别上违反,都不会造成太大的影响。实际应用中的类都要复杂的多,一旦发生职责扩散而需要修改类时,除非这个类本身非常简单,否则还是遵循单一职责原则的好。
遵循单一职责原的优点有:
- 可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多;
- 提高类的可读性,提高系统的可维护性;
- 变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响。
需要说明的一点是单一职责原则不只是面向对象编程思想所特有的,只要是模块化的程序设计,都适用单一职责原则。
肯定有不少人跟我刚看到这项原则的时候一样,对这个原则的名字充满疑惑。其实原因就是这项原则最早是在1988年,由麻省理工学院的一位姓里的女士(Barbara Liskov)提出来的。
定义1:如果对每一个类型为 T1的对象 o1,都有类型为 T2 的对象o2,使得以 T1定义的所有程序 P 在所有的对象 o1 都代换成 o2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。
定义2:所有引用基类的地方必须能透明地使用其子类的对象。
问题由来:有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
解决方案:当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
继承作为面向对象三大特性之一,在给程序设计带来巨大便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低,增加了对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能会产生故障。
举例说明继承的风险,我们需要完成一个两数相减的功能,由类A来负责。
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}
|
运行结果:
100-50=50
100-80=20
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
- 两数相减。
- 两数相加,然后再加100。
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
|
类B完成后,运行结果:
100-50=150
100-80=180
100+20+100=220
我们发现原本运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B重写后的方法,造成原本运行正常的功能出现了错误。在本例中,引用基类A完成的功能,换成子类B之后,发生了异常。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的几率非常大。如果非要重写父类的方法,比较通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。它包含以下4层含义:
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
- 子类中可以增加自己特有的方法。
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
- 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
看上去很不可思议,因为我们会发现在自己编程中常常会违反里氏替换原则,程序照样跑的好好的。所以大家都会产生这样的疑问,假如我非要不遵循里氏替换原则会有什么后果?
后果就是:你写的代码出问题的几率将会大大增加。
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
依赖倒置原则的核心思想是面向接口编程,我们依旧用一个例子来说明面向接口编程比相对于面向实现编程好在什么地方。场景是这样的,母亲给孩子讲故事,只要给她一本书,她就可以照着书给孩子讲故事了。代码如下:
class Book{
public String getContent(){
return "很久很久以前有一个阿拉伯的故事……";
}
}
class Mother{
public void narrate(Book book){
System.out.println("妈妈开始讲故事");
System.out.println(book.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
}
}
|
运行结果:
妈妈开始讲故事
很久很久以前有一个阿拉伯的故事……
运行良好,假如有一天,需求变成这样:不是给书而是给一份报纸,让这位母亲讲一下报纸上的故事,报纸的代码如下:
class Newspaper{
public String getContent(){
return "林书豪38+7领导尼克斯击败湖人……";
}
}
|
这位母亲却办不到,因为她居然不会读报纸上的故事,这太荒唐了,只是将书换成报纸,居然必须要修改Mother才能读。假如以后需求换成杂志呢?换成网页呢?还要不断地修改Mother,这显然不是好的设计。原因就是Mother与Book之间的耦合性太高了,必须降低他们之间的耦合度才行。
我们引入一个抽象的接口IReader。读物,只要是带字的都属于读物:
interface IReader{
public String getContent();
}
|
Mother类与接口IReader发生依赖关系,而Book和Newspaper都属于读物的范畴,他们各自都去实现IReader接口,这样就符合依赖倒置原则了,代码修改为:
class Newspaper implements IReader {
public String getContent(){
return "林书豪17+9助尼克斯击败老鹰……";
}
}
class Book implements IReader{
public String getContent(){
return "很久很久以前有一个阿拉伯的故事……";
}
}
class Mother{
public void narrate(IReader reader){
System.out.println("妈妈开始讲故事");
System.out.println(reader.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
mother.narrate(new Newspaper());
}
}
|
运行结果:
妈妈开始讲故事
很久很久以前有一个阿拉伯的故事……
妈妈开始讲故事
林书豪17+9助尼克斯击败老鹰……
这样修改后,无论以后怎样扩展Client类,都不需要再修改Mother类了。这只是一个简单的例子,实际情况中,代表高层模块的Mother类将负责完成主要的业务逻辑,一旦需要对它进行修改,引入错误的风险极大。所以遵循依赖倒置原则可以降低类之间的耦合性,提高系统的稳定性,降低修改程序造成的风险。
采用依赖倒置原则给多人并行开发带来了极大的便利,比如上例中,原本Mother类与Book类直接耦合时,Mother类必须等Book类编码完成后才可以进行编码,因为Mother类依赖于Book类。修改后的程序则可以同时开工,互不影响,因为Mother与Book类一点关系也没有。参与协作开发的人越多、项目越庞大,采用依赖导致原则的意义就越重大。现在很流行的TDD开发模式就是依赖倒置原则最成功的应用。
传递依赖关系有三种方式,以上的例子中使用的方法是接口传递,另外还有两种传递方式:构造方法传递和setter方法传递,相信用过Spring框架的,对依赖的传递方式一定不会陌生。
在实际编程中,我们一般需要做到如下3点:
- 低层模块尽量都要有抽象类或接口,或者两者都有。
- 变量的声明类型尽量是抽象类或接口。
- 使用继承时遵循里氏替换原则。
依赖倒置原则的核心就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置。
定义:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
问题由来:类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法。
解决方案:将臃肿的接口I拆分为独立的几个接口,类A和类C分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则。
举例来说明接口隔离原则:
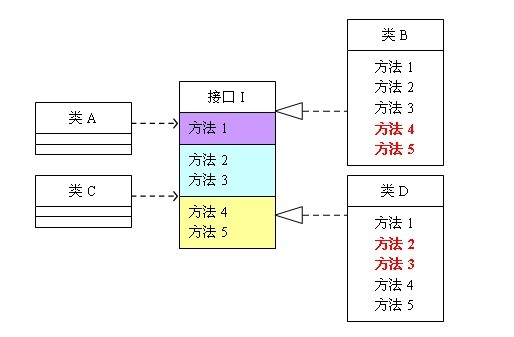
(图1 未遵循接口隔离原则的设计)
这个图的意思是:类A依赖接口I中的方法1、方法2、方法3,类B是对类A依赖的实现。类C依赖接口I中的方法1、方法4、方法5,类D是对类C依赖的实现。对于类B和类D来说,虽然他们都存在着用不到的方法(也就是图中红色字体标记的方法),但由于实现了接口I,所以也必须要实现这些用不到的方法。对类图不熟悉的可以参照程序代码来理解,代码如下:
interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class A{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method2();
}
public void depend3(I i){
i.method3();
}
}
class B implements I{
public void method1() {
System.out.println("类B实现接口I的方法1");
}
public void method2() {
System.out.println("类B实现接口I的方法2");
}
public void method3() {
System.out.println("类B实现接口I的方法3");
}
//对于类B来说,method4和method5不是必需的,但是由于接口A中有这两个方法,
//所以在实现过程中即使这两个方法的方法体为空,也要将这两个没有作用的方法进行实现。
public void method4() {}
public void method5() {}
}
class C{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method4();
}
public void depend3(I i){
i.method5();
}
}
class D implements I{
public void method1() {
System.out.println("类D实现接口I的方法1");
}
//对于类D来说,method2和method3不是必需的,但是由于接口A中有这两个方法,
//所以在实现过程中即使这两个方法的方法体为空,也要将这两个没有作用的方法进行实现。
public void method2() {}
public void method3() {}
public void method4() {
System.out.println("类D实现接口I的方法4");
}
public void method5() {
System.out.println("类D实现接口I的方法5");
}
}
public class Client{
public static void main(String[] args){
A a = new A();
a.depend1(new B());
a.depend2(new B());
a.depend3(new B());
C c = new C();
c.depend1(new D());
c.depend2(new D());
c.depend3(new D());
}
}
|
可以看到,如果接口过于臃肿,只要接口中出现的方法,不管对依赖于它的类有没有用处,实现类中都必须去实现这些方法,这显然不是好的设计。如果将这个设计修改为符合接口隔离原则,就必须对接口I进行拆分。在这里我们将原有的接口I拆分为三个接口,拆分后的设计如图2所示:
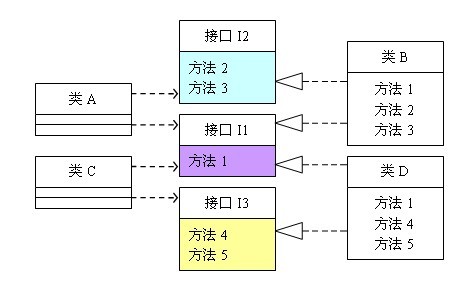
(图2 遵循接口隔离原则的设计)
照例贴出程序的代码,供不熟悉类图的朋友参考:
interface I1 {
public void method1();
}
interface I2 {
public void method2();
public void method3();
}
interface I3 {
public void method4();
public void method5();
}
class A{
public void depend1(I1 i){
i.method1();
}
public void depend2(I2 i){
i.method2();
}
public void depend3(I2 i){
i.method3();
}
}
class B implements I1, I2{
public void method1() {
System.out.println("类B实现接口I1的方法1");
}
public void method2() {
System.out.println("类B实现接口I2的方法2");
}
public void method3() {
System.out.println("类B实现接口I2的方法3");
}
}
class C{
public void depend1(I1 i){
i.method1();
}
public void depend2(I3 i){
i.method4();
}
public void depend3(I3 i){
i.method5();
}
}
class D implements I1, I3{
public void method1() {
System.out.println("类D实现接口I1的方法1");
}
public void method4() {
System.out.println("类D实现接口I3的方法4");
}
public void method5() {
System.out.println("类D实现接口I3的方法5");
}
}
|
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。本文例子中,将一个庞大的接口变更为3个专用的接口所采用的就是接口隔离原则。在程序设计中,依赖几个专用的接口要比依赖一个综合的接口更灵活。接口是设计时对外部设定的“契约”,通过分散定义多个接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
说到这里,很多人会觉的接口隔离原则跟之前的单一职责原则很相似,其实不然。其一,单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离。其二,单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要约束接口接口,主要针对抽象,针对程序整体框架的构建。
采用接口隔离原则对接口进行约束时,要注意以下几点:
- 接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
- 为依赖接口的类定制服务,只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
运用接口隔离原则,一定要适度,接口设计的过大或过小都不好。设计接口的时候,只有多花些时间去思考和筹划,才能准确地实践这一原则。
定义:一个对象应该对其他对象保持最少的了解。
问题由来:类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
解决方案:尽量降低类与类之间的耦合。
自从我们接触编程开始,就知道了软件编程的总的原则:低耦合,高内聚。无论是面向过程编程还是面向对象编程,只有使各个模块之间的耦合尽量的低,才能提高代码的复用率。低耦合的优点不言而喻,但是怎么样编程才能做到低耦合呢?那正是迪米特法则要去完成的。
迪米特法则又叫最少知道原则,最早是在1987年由美国Northeastern University的Ian Holland提出。通俗的来讲,就是一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。迪米特法则还有一个更简单的定义:只与直接的朋友通信。首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
举一个例子:有一个集团公司,下属单位有分公司和直属部门,现在要求打印出所有下属单位的员工ID。先来看一下违反迪米特法则的设计。
//总公司员工
class Employee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
//分公司员工
class SubEmployee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//为分公司人员按顺序分配一个ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//为总公司人员按顺序分配一个ID
emp.setId("总公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
List<SubEmployee> list1 = sub.getAllEmployee();
for(SubEmployee e:list1){
System.out.println(e.getId());
}
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
public class Client{
public static void main(String[] args){
CompanyManager e = new CompanyManager();
e.printAllEmployee(new SubCompanyManager());
}
}
|
现在这个设计的主要问题出在CompanyManager中,根据迪米特法则,只与直接的朋友发生通信,而SubEmployee类并不是CompanyManager类的直接朋友(以局部变量出现的耦合不属于直接朋友),从逻辑上讲总公司只与他的分公司耦合就行了,与分公司的员工并没有任何联系,这样设计显然是增加了不必要的耦合。按照迪米特法则,应该避免类中出现这样非直接朋友关系的耦合。修改后的代码如下:
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//为分公司人员按顺序分配一个ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
public void printEmployee(){
List<SubEmployee> list = this.getAllEmployee();
for(SubEmployee e:list){
System.out.println(e.getId());
}
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//为总公司人员按顺序分配一个ID
emp.setId("总公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
sub.printEmployee();
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
|
修改后,为分公司增加了打印人员ID的方法,总公司直接调用来打印,从而避免了与分公司的员工发生耦合。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系,例如本例中,总公司就是通过分公司这个“中介”来与分公司的员工发生联系的。过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
开闭原则是面向对象设计中最基础的设计原则,它指导我们如何建立稳定灵活的系统。开闭原则可能是设计模式六项原则中定义最模糊的一个了,它只告诉我们对扩展开放,对修改关闭,可是到底如何才能做到对扩展开放,对修改关闭,并没有明确的告诉我们。以前,如果有人告诉我“你进行设计的时候一定要遵守开闭原则”,我会觉的他什么都没说,但貌似又什么都说了。因为开闭原则真的太虚了。
在仔细思考以及仔细阅读很多设计模式的文章后,终于对开闭原则有了一点认识。其实,我们遵循设计模式前面5大原则,以及使用23种设计模式的目的就是遵循开闭原则。也就是说,只要我们对前面5项原则遵守的好了,设计出的软件自然是符合开闭原则的,这个开闭原则更像是前面五项原则遵守程度的“平均得分”,前面5项原则遵守的好,平均分自然就高,说明软件设计开闭原则遵守的好;如果前面5项原则遵守的不好,则说明开闭原则遵守的不好。
其实笔者认为,开闭原则无非就是想表达这样一层意思:用抽象构建框架,用实现扩展细节。因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节,我们用从抽象派生的实现类来进行扩展,当软件需要发生变化时,我们只需要根据需求重新派生一个实现类来扩展就可以了。当然前提是我们的抽象要合理,要对需求的变更有前瞻性和预见性才行。
说到这里,再回想一下前面说的5项原则,恰恰是告诉我们用抽象构建框架,用实现扩展细节的注意事项而已:单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲,他告诉我们要对扩展开放,对修改关闭。
最后说明一下如何去遵守这六个原则。对这六个原则的遵守并不是是和否的问题,而是多和少的问题,也就是说,我们一般不会说有没有遵守,而是说遵守程度的多少。任何事都是过犹不及,设计模式的六个设计原则也是一样,制定这六个原则的目的并不是要我们刻板的遵守他们,而需要根据实际情况灵活运用。对他们的遵守程度只要在一个合理的范围内,就算是良好的设计。我们用一幅图来说明一下。

图中的每一条维度各代表一项原则,我们依据对这项原则的遵守程度在维度上画一个点,则如果对这项原则遵守的合理的话,这个点应该落在红色的同心圆内部;如果遵守的差,点将会在小圆内部;如果过度遵守,点将会落在大圆外部。一个良好的设计体现在图中,应该是六个顶点都在同心圆中的六边形。
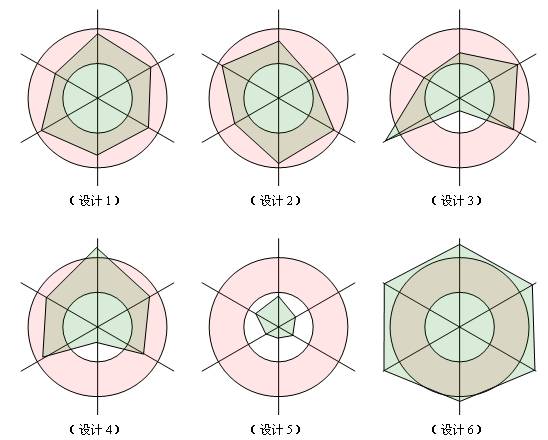
在上图中,设计1、设计2属于良好的设计,他们对六项原则的遵守程度都在合理的范围内;设计3、设计4设计虽然有些不足,但也基本可以接受;设计5则严重不足,对各项原则都没有很好的遵守;而设计6则遵守过渡了,设计5和设计6都是迫切需要重构的设计。
到这里,设计模式的六大原则就写完了。主要参考书籍有《设计模式》《设计模式之禅》《大话设计模式》以及网上一些零散的文章,但主要内容主要还是我本人对这六个原则的感悟。写出来的目的一方面是对这六项原则系统地整理一下,一方面也与广大的网友分享,因为设计模式对编程人员来说,的确非常重要。正如有句话叫做一千个读者眼中有一千个哈姆雷特,如果大家对这六项原则的理解跟我有所不同,欢迎留言,大家共同探讨。
Article From:http://www.uml.org.cn/sjms/201211023.asp
Longronglin之设计模式
Article From: http://blog.csdn.net/longronglin/article/details/1454315
Christopher Alexander 说过:“每一个模式描述了一个在我们周围不断重复发生的问题,以及该问题的解决方案的核心。这样,你就能一次又一次地使用该方案而不必做重复劳动”。
模式描述为:在一定环境中解决某一问题的方案,包括三个基本元素--问题,解决方案和环境。
阅读类图和对象图请先学习UML
创建模式 结构模式 行为模式
创建模式:对类的实例化过程的抽象。一些系统在创建对象时,需要动态地决定怎样创建对象,创建哪些对象,以及如何组合和表示这些对象。创建模式描述了怎样构造和封装这些动态的决定。包含类的创建模式和对象的创建模式。
结构模式:描述如何将类或对象结合在一起形成更大的结构。分为类的结构模式和对象的结构模式。类的结构模式使用继承把类,接口等组合在一起,以形成更大的结构。类的结构模式是静态的。对象的结构模式描述怎样把各种不同类型的对象组合在一起,以实现新的功能的方法。对象的结构模式是动态的。
行为模式:对在不同的对象之间划分责任和算法的抽象化。不仅仅是关于类和对象的,并是关于他们之间的相互作用。类的行为模式使用继承关系在几个类之间分配行为。对象的行为模式则使用对象的聚合来分配行为。
设计模式使用排行:
|
频率
|
所属类型
|
模式名称
|
模式
|
简单定义
|
|
5
|
创建型
|
Singleton
|
单件
|
保证一个类只有一个实例,并提供一个访问它的全局访问点。
|
|
5
|
结构型
|
组合模式
|
将对象组合成树形结构以表示部分整体的关系,Composite使得用户对单个对象和组合对象的使用具有一致性。
|
|
|
5
|
结构型
|
FAÇADE
|
外观
|
为子系统中的一组接口提供一致的界面,facade提供了一高层接口,这个接口使得子系统更容易使用。
|
|
5
|
结构型
|
Proxy
|
代理
|
为其他对象提供一种代理以控制对这个对象的访问
|
|
5
|
行为型
|
迭代器
|
提供一个方法顺序访问一个聚合对象的各个元素,而又不需要暴露该对象的内部表示。
|
|
|
5
|
行为型
|
Observer
|
观察者
|
定义对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知自动更新。
|
|
5
|
行为型
|
Template Method
|
模板方法
|
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,Template Method使得子类可以不改变一个算法的结构即可以重定义该算法得某些特定步骤。
|
|
4
|
创建型
|
Abstract Factory
|
抽象工厂
|
提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们的具体类。
|
|
4
|
创建型
|
Factory Method
|
工厂方法
|
定义一个用于创建对象的接口,让子类决定实例化哪一个类,Factory Method使一个类的实例化延迟到了子类。
|
|
4
|
结构型
|
Adapter
|
适配器
|
将一类的接口转换成客户希望的另外一个接口,Adapter模式使得原本由于接口不兼容而不能一起工作那些类可以一起工作。
|
|
4
|
结构型
|
Decorator
|
装饰
|
动态地给一个对象增加一些额外的职责,就增加的功能来说,Decorator模式相比生成子类更加灵活。
|
|
4
|
行为型
|
Command
|
命令
|
将一个请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,对请求排队和记录请求日志,以及支持可撤销的操作。
|
|
4
|
行为型
|
State
|
状态
|
允许对象在其内部状态改变时改变他的行为。对象看起来似乎改变了他的类。
|
|
4
|
行为型
|
Strategy
|
策略模式
|
定义一系列的算法,把他们一个个封装起来,并使他们可以互相替换,本模式使得算法可以独立于使用它们的客户。
|
|
3
|
创建型
|
Builder
|
生成器
|
将一个复杂对象的构建与他的表示相分离,使得同样的构建过程可以创建不同的表示。
|
|
3
|
结构型
|
Bridge
|
桥接
|
将抽象部分与它的实现部分相分离,使他们可以独立的变化。
|
|
3
|
行为型
|
China of Responsibility
|
职责链
|
使多个对象都有机会处理请求,从而避免请求的送发者和接收者之间的耦合关系
|
|
2
|
创建型
|
Prototype
|
原型
|
用原型实例指定创建对象的种类,并且通过拷贝这些原型来创建新的对象。
|
|
2
|
结构型
|
享元
|
享元模式以共享的方式高效的支持大量的细粒度对象。享元模式能做到共享的关键是区分内蕴状态和外蕴状态。内蕴状态存储在享元内部,不会随环境的改变而有所不同。外蕴状态是随环境的改变而改变的。
|
|
|
2
|
行为型
|
Mediator
|
中介者
|
用一个中介对象封装一些列的对象交互。
|
|
2
|
行为型
|
Visitor
|
访问者模式
|
表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素类的前提下定义作用于这个元素的新操作。
|
|
1
|
行为型
|
解释器
|
给定一个语言,定义他的文法的一个表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
|
|
|
1
|
行为型
|
Memento
|
备忘录
|
在不破坏对象的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
|
一 : 单例模式(Singleton)
单例模式:Singleton的作用是保证在应用程序中,一个类Class只有一个实例存在。并提供全局访问。
结构:

账本类:1 单一实例 2 给多个对象共享 3 自己创建
网页计数器
public class LazySingleton
public class LazySingleton
{
private static LazySingleton newInstance = null;
private static LazySingleton newInstance = null;
private LazySingleton ()
{
}
public static synchronized LazySingleton getInstance ()
{
if (newInstance == null)
if (newInstance == null)
{
newInstance = new LazySingleton ();
}
return newInstance;
}
newInstance = new LazySingleton ();
}
return newInstance;
}
}
singleton限制了实例个数,有利于gc的回收。
singleton限制了实例个数,有利于gc的回收。
二:策略模式(Strategy)
策略模式:策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。策略模式把行为和环境分开。环境类负责维持和查询行为类,各种算法在具体的策略类中提供。由于算法和环境独立开来,算法的增减,修改都不会影响到环境和客户端。
结构:

使用QQ泡MM时使用外挂 客户端 :ME 抽象类: 外挂 具体:策略(图片,笑话,名人名言)
图书销售算法(不同书本折扣的算法)
三:原型模式(Prototype)
原型模式:通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的方法创建出更多同类型的对象。原始模型模式允许动态的增加或减少产品类,产品类不需要非得有任何事先确定的等级结构,原始模型模式适用于任何的等级结构。缺点是每一个类都必须配备一个克隆方法
结构:

复印技术: 1 不是同一个对象 2 属同类
短消息(转发) 1-n个MM
因为Java中的提供clone()方法来实现对象的克隆,所以Prototype模式实现一下子变得很简单.
四:门面模式(Façade)
门面模式:外部与一个子系统的通信必须通过一个统一的门面对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用,减少复杂性。每一个子系统只有一个门面类,而且此门面类只有一个实例,也就是说它是一个单例模式。但整个系统可以有多个门面类。
1 门面角色 2 子系统角色
结构:

Facade典型应用就是数据库JDBC的应用和Session的应用
五:备忘录模式(Memento)
Memento模式:Memento对象是一个保存另外一个对象内部状态拷贝的对象,这样以后就可以将该对象恢复到原先保存的状态。模式的用意是在不破坏封装的条件下,将一个对象的状态捕捉住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。模式所涉及的角色有三个,备忘录角色、发起人角色和负责人角色。
备忘录角色的作用:
(1) 将发起人对象的内部状态存储起来,备忘录可以根据发起人对象的判断来决定存储多少发起人对象的内部状态。
(2) 备忘录可以保护其内容不被发起人对象之外的任何对象所读取。
发起人角色的作用:
(1) 创建一个含有当前内部状态的备忘录对象。
(2) 使用备忘录对象存储其内部状态。
负责人角色的作用:
(1) 负责保存备忘录对象。
(2) 不检查备忘录对象的内容
结构:

备份系统时使用
GHOST
六 : 命令模式(Command)
命令模式:命令模式把一个请求或者操作封装到一个对象中。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。命令模式允许请求的一方和发送的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否执行,何时被执行以及是怎么被执行的。系统支持命令的撤消。
结构:

MM(客户端)--àME(请求者)--à命令角色--à(具体命令)-à代理处(接收者)--àMM
上网 IE 输入 http地址 发送命令
七: 解释器(Interpreter)
解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何排列组合都是一个语言。
结构:

编译原理之编译器
文言文注释:一段文言文,将它翻译成白话文
八:调停者模式(Mediator)
调停者模式:包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使他们可以松散偶合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用。保证这些作用可以彼此独立的变化。调停者模式将多对多的相互作用转化为一对多的相互作用。调停者模式将对象的行为和协作抽象化,把对象在小尺度的行为上与其他对象的相互作用分开处理。
结构:

法院和原告,被告的关系
九:责任链模式(CHAIN OF RESPONSIBLEITY)
责任链模式:执行者的不确定性 在责任链模式中,很多对象由每一个对象对其下家的引用而接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。客户并不知道链上的哪一个对象最终处理这个请求,系统可以在不影响客户端的情况下动态的重新组织链和分配责任。处理者有两个选择:承担责任或者把责任推给下家。一个请求可以最终不被任何接收端对象所接受。
结构:

典型的对象结构:

喝酒时通过成语接龙决定谁喝酒(马到成功-功不可没-没完没了)
十:工厂模式(Factory)
工厂模式:定义一个用于创建对象的接口,让接口子类通过工厂方法决定实例化哪一个类。
结构:

水果园—〉(葡萄园,苹果园)--〉(葡萄,苹果)(各自生产)
十一:抽象工厂模式(Abstract Factory)
抽象工厂模式:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
结构:

女娲造人---〉(阴,阳)--〉(人,兽)----〉(男人,女人,公兽,母兽)(人和兽属于不同的产品类)
十二:建造模式(Builder)
建造模式:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示.Builder模式是一步一步创建一个复杂的对象,它允许用户可以只通过指定复杂对象的类型和内容就可以构建它们.用户不知道内部的具体构建细节.Builder模式是非常类似抽象工厂模式,细微的区别大概只有在反复使用中才能体会到。
将产品的内部表象和产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。建造模式使得产品内部表象可以独立的变化,客户不必知道产品内部组成的细节。建造模式可以强制实行一种分步骤进行的建造过程。
结构:

交互图:
汽车制造
合成模式:将对象以树形结构组织起来,以达成“部分-整体” 的层次结构,使得客户端对单个对象和组合对象的使用具有一致性. 合成模式就是一个处理对象的树结构的模式。合成模式把部分与整体的关系用树结构表示出来。合成模式使得客户端把一个个单独的成分对象和由他们复合而成的合成对象同等看待。
结构:

windows的目录树(文件系统)
十四:装饰模式(DECORATOR)
装饰模式:装饰模式以对客户端透明的方式扩展对象的功能,是继承关系的一个替代方案,提供比继承更多的灵活性。动态给一个对象增加功能,这些功能可以再动态的撤消。增加由一些基本功能的排列组合而产生的非常大量的功能。
结构:

在visio中文件可以使用背景进行装饰
变废为宝
十五:设计模式之Adapter(适配器)
适配器模式:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口原因不匹配而无法一起工作的两个类能够一起工作。适配类可以根据参数返还一个合适的实例给客户端
将两个不兼容的类纠合在一起使用,属于结构型模式,需要Adaptee(被适配者)和Adaptor(适配器)两个身份.
将两个不兼容的类纠合在一起使用,属于结构型模式,需要Adaptee(被适配者)和Adaptor(适配器)两个身份.
为何使用?
我们经常碰到要将两个没有关系的类组合在一起使用,第一解决方案是:修改各自类的接口,但是如果我们没有源代码,或者,我们不愿意为了一个应用而修改各自的接口。 怎么办? 使用Adapter,在这两种接口之间创建一个混合接口(混血儿).
我们经常碰到要将两个没有关系的类组合在一起使用,第一解决方案是:修改各自类的接口,但是如果我们没有源代码,或者,我们不愿意为了一个应用而修改各自的接口。 怎么办? 使用Adapter,在这两种接口之间创建一个混合接口(混血儿).
结构:

对象结构:

充电器(手机和220V电压)
十六:桥梁模式(Bridge)
桥梁模式:将抽象化与实现化脱耦,使得二者可以独立的变化。也就是说将他们之间的强关联变成弱关联,也就是指在一个软件系统的抽象化和实现化之间使用组合/聚合关系而不是继承关系,从而使两者可以独立的变化。
结构:

jdbc驱动程序
十七:代理模式(Proxy)
代理模式:代理模式给某一个对象提供一个代理对象,并由代理对象控制对源对象的引用。代理就是一个人或一个机构代表另一个人或者一个机构采取行动。某些情况下,客户不想或者不能够直接引用一个对象,代理对象可以在客户和目标对象直接起到中介的作用。客户端分辨不出代理主题对象与真实主题对象。代理模式可以并不知道真正的被代理对象,而仅仅持有一个被代理对象的接口,这时候代理对象不能够创建被代理对象,被代理对象必须有系统的其他角色代为创建并传入。
结构:

运行时的代理结构:

用代理服务器连接出网
销售代理(厂商)律师代理(客户)
foxmail
枪手
十八:享元模式(Flyweight)
享元模式以共享的方式高效的支持大量的细粒度对象。享元模式能做到共享的关键是区分内蕴状态和外蕴状态。内蕴状态存储在享元内部,不会随环境的改变而有所不同。外蕴状态是随环境的改变而改变的。外蕴状态不能影响内蕴状态,它们是相互独立的。将可以共享的状态和不可以共享的状态从常规类中区分开来,将不可以共享的状态从类里剔除出去。客户端不可以直接创建被共享的对象,而应当使用一个工厂对象负责创建被共享的对象。享元模式大幅度的降低内存中对象的数量。
结构:

共享方法:

字体的26个字母和各自的斜体等
十九:状态模式(State)
状态模式:状态模式允许一个对象在其内部状态改变的时候改变行为。这个对象看上去象是改变了它的类一样。状态模式把所研究的对象的行为包装在不同的状态对象里,每一个状态对象都属于一个抽象状态类的一个子类。状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。状态模式需要对每一个系统可能取得的状态创立一个状态类的子类。当系统的状态变化时,系统便改变所选的子类。
结构:

人心情不同时表现不同有不同的行为
编钟
登录login logout
二十:观察者模式(Observer)
观察者模式:观察者模式定义了一种一队多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自动更新自己。发布订阅。
结构:

公司邮件系统everyone@sina.com的应用。当公司员工向这个邮箱发邮件时会发给公司的每一个员工。如果设置了Outlook则会及时收到通知。
接收到短消息
二十一:模板方法模式(Template)
模板方法模式:模板方法模式准备一个抽象类,将部分逻辑以具体方法以及具体构造子的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。先制定一个顶级逻辑框架,而将逻辑的细节留给具体的子类去实现。
结构:

使用网页设计时使用的模板架构网页(骨架) 算法的各个逻辑系统
二十二:访问者模式(Visitor)
访问者模式:访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。访问者模式适用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由的演化。访问者模式使得增加新的操作变的很容易,就是增加一个新的访问者类。访问者模式将有关的行为集中到一个访问者对象中,而不是分散到一个个的节点类中。当使用访问者模式时,要将尽可能多的对象浏览逻辑放在访问者类中,而不是放到它的子类中。访问者模式可以跨过几个类的等级结构访问属于不同的等级结构的成员类。
结构:

电脑销售系统: 访问者(自己)---〉电脑配置系统(主板,CPU,内存。。。。。。)
二十三:迭代子模式(Iterator)
迭代子模式:迭代子模式可以顺序访问一个聚集中的元素而不必暴露聚集的内部表象。多个对象聚在一起形成的总体称之为聚集,聚集对象是能够包容一组对象的容器对象。迭代子模式将迭代逻辑封装到一个独立的子对象中,从而与聚集本身隔开。迭代子模式简化了聚集的界面。每一个聚集对象都可以有一个或一个以上的迭代子对象,每一个迭代子的迭代状态可以是彼此独立的。迭代算法可以独立于聚集角色变化。
结构:

查询数据库,返回结果集(map, list, set)
二十四:MVC模式
MVC还使用了的设计模式,如:用来指定视图缺省控制器的Factory Method和用来增加视图滚动的Decorator。但是MVC的主要关系还是由Observer、Composite和Strategy三个设计模式给出的。

struts应用 spring 应用
设计模式的使用:
模式关系图:

个人图解:(^_^)没有看到下面的图解时想的
门面模式可以使用一个单体实例对象实现
抽象工厂可以创建单体实例 也可以使用工厂方法也可以使用原型创建对象实例
模板方法可以使用工厂方法实现创建实例使用策略模式定义算法使用
策略模式可以使用享元实例 与装饰模式可以相互使用
享元模式被状态,解释器,合成等模式。共享
解释器模式通过访问模式实现其动作 通过享元实现基本元素的共享
装饰模式使用策略可以实现不同的装饰效果
迭代器模式通过访问者访问对象元素 通过备忘录模式实现纪录的记忆功能 访问合成的对象
命令模式通过使用备忘录模式(参考) 执行命令
建造模式可以使用合成模式创建合成产品
责任链模式使用合成模式定义链
调停者模式可以使观察者的观察受其影响
实际图解:
关模式(相互关系):
Abstract Factory类通常用工厂方法(Factory Method)实现,但它们也可以用Prototype实现。一个具体的工厂通常是一个单件Singleton。Abstract Factory与Builder相似,因为它也可以创建复杂对象。主要的区别是Builder模式着重于一步步构造一个复杂对象。而Abstract Factory着重于多个系列的产品对象(简单的或是复杂的)。Builder在最后一步返回产品,而对于Abstract Factory来说,产品是立即返回的。Composite通常是用Builder生成的。
Factory方法通常在Template Methods中被调用。Prototypes不需要创建Creator的子类。但是,它们通常要求一个针对Product类的Initialize操作。Creator使用Initialize来初始化对象。Factory Method不需要这样的操作。多态迭代器靠Factory Method来例化适当的迭代器子类。Factory Method模式常被模板方法调用。
Prototype和Abstract Factory模式在某种方面是相互竞争的。但是它们也可以一起使用。Abstract Factory可以存储一个被克隆的原型的集合,并且返回产品对象。大量使用Composite和Decorator模式的设计通常也可从Prototype模式处获益。
很多模式可以使用Singleton模式实现。参见Abstract Factory、Builder,和Prototype。
模式Bridge的结构与对象适配器类似,但是Bridge模式的出发点不同;Bridge目的是将接口部分和实现部分分离,从而对它们可以较为容易也相对独立的加以改变。而Adapter则意味着改变一个已有对象的接口。
Decorator模式增强了其他对象的功能而同时又不改变它的接口。因此Decorator对应用程序的透明性比适配器要好。结果是Decorator支持递归组合,而纯粹使用适配器是不可能实现这一点的。模式Proxy在不改变它的接口的条件下,为另一个对象定义了一个代理。Abstract Factory模式可以用来创建和配置一个特定的Bridge模式。
Adapter模式用来帮助无关的类协同工作,它通常在系统设计完成后才会被使用。然而,Bridge模式则是在系统开始时就被使用,它使得抽象接口和实现部分可以独立进行改变。适配器Adapter为它所适配的对象提供了一个不同的接口。相反,代理提供了与它的实体相同的接口。然而,用于访问保护的代理可能会拒绝执行实体会执行的操作,因此,它的接口实际上可能只是实体接口的一个子集。
Decorator模式经常与Composite模式一起使用。当装饰和组合一起使用时,它们通常有一个公共的父类。因此装饰必须支持具有Add、Remove和GetChild 操作。Decorator模式不同于Adapter模式,因为装饰仅改变对象的职责而不改变它的接口;而适配器将给对象一个全新的接口。Composite模式可以将装饰视为一个退化的、仅有一个组件的组合。然而,装饰仅给对象添加一些额外的职责—它的目的不在于对象聚集。用一个装饰你可以改变对象的外表;而Strategy模式使得你可以改变对象的内核。这是改变对象的两种途径。
尽管Decorator的实现部分与Proxy相似,但Decorator的目的不一样。Decorator为对象添加一个或多个功能,而代理则控制对对象的访问。代理的实现Decorator的实现类似,但是在相似的程度上有所差别。Protection Proxy的实现可能与Decorator的实现差不多。另一方面, Remote Proxy不包含对实体的直接引用,而只是一个间接引用,如“主机I D,主机上的局部地址。”Virtual Proxy开始的时候使用一个间接引用,例如一个文件名,但最终将获取并使用一个直接引用。
Abstract Factory模式可以与Facade模式一起使用以提供一个接口,这一接口可用来以一种子系统独立的方式创建子系统对象。Abstract Factory也可以代替Facade模式隐藏那些与平台相关的类。Mediator模式与Facade模式的相似之处是,它抽象了一些已有的类的功能。然而,Mediator的目的是对同事之间的任意通讯进行抽象,通常集中不属于任何单个对象的功能。Mediator的同事对象知道中介者并与它通信,而不是直接与其他同类对象通信。相对而言,Facade模式仅对子系统对象的接口进行抽象,从而使它们更容易使用;它并不定义新功能,子系统也不知道Facade的存在。通常来讲,仅需要一个Facade对象,因此Facade对象通常属于Singleton模式
Memento可用来保持某个状态,命令用这一状态来取消它的效果。在被放入历史表列前必须被拷贝的命令起到一种原型的作用。Memento常与迭代器模式一起使用。迭代器可使用一个Memento来捕获一个迭代的状态。迭代器在其内部存储Memento。
Iterator解释器可用一个迭代器遍历该结构。
Visitor可用来在一个类中维护抽象语法树中的各节点的行为。访问者可以用于对一个由Composite模式定义的对象结构进行操作。迭代器常被应用到象复合这样的递归结构上。
Facade与中介者的不同之处在于它是对一个对象子系统进行抽象,从而提供了一个更为方便的接口。它的协议是单向的,即Facade对象对这个子系统类提出请求,但反之则不行。相反, Mediator提供了各Colleague对象不支持或不能支持的协作行为,而且协议是多向的。Colleague可使用Observer模式与Mediator通信。
Command命令可使用备忘录来为可撤消的操作维护状态。如前所述备忘录可用于迭代。
Mediator通过封装复杂的更新语义。
Singleton使用Singleton模式来保证它是唯一的并且是可全局访问的。
Strategy模板方法使用继承来改变算法的一部分。Strategy使用委托来改变整个算法。
Interpreter访问者可以用于解释。
创建型模式的讨论
用一个系统创建的那些对象的类对系统进行参数化有两种常用方法。一种是生成创建对象的类的子类;这对应于使用Factory Method模式。这种方法的主要缺点是,仅为了改变产品类,就可能需要创建一个新的子类。这样的改变可能是级联的(Cascade)。例如,如果产品的创建者本身是由一个工厂方法创建的,那么你也必须重定义它的创建者。另一种对系统进行参数化的方法更多的依赖于对象复合:定义一个对象负责明确产品对象的类,并将它作为该系统的参数。这是Abstract Factory、Builder和Prototype模式的关键特征。所有这三个模式都涉及到创建一个新的负责创建产品对象的“工厂对象”。Abstract Factory由这个工厂对象产生多个类的对象。Builder由这个工厂对象使用一个相对复杂的协议,逐步创建一个复杂产品。Prototype由该工厂对象通过拷贝原型对象来创建产品对象。在这种情况下,因为原型负责返回产品对象,所以工厂对象和原型是同一个对象。
结构型模式的讨论
你可能已经注意到了结构型模式之间的相似性,尤其是它们的参与者和协作之间的相似性。这可能是因为结构型模式依赖于同一个很小的语言机制集合构造代码和对象:单继承和多重继承机制用于基于类的模式,而对象组合机制用于对象式模式。但是这些相似性掩盖了这些模式的不同意图。在本节中,我们将对比这些结构型模式,使你对它们各自的优点有所了解。
Adapter与Bridge
Adapter模式和Bridge模式具有一些共同的特征。它们都给另一对象提供了一定程度上的间接性,因而有利于系统的灵活性。它们都涉及到从自身以外的一个接口向这个对象转发请求。这些模式的不同之处主要在于它们各自的用途。Bridge模式主要是为了解决两个已有接口之间不匹配的问题。它不考虑这些接口是怎样实现的,也不考虑它们各自可能会如何演化。这种方式不需要对两个独立设计的类中的任一个进行重新设计,就能够使它们协同工作。另一方面, Bridge模式则对抽象接口与它的(可能是多个)实现部分进行桥接。虽然这一模式允许你修改实现它的类,它仍然为用户提供了一个稳定的接口。Bridge模式也会在系统演化时适应新的实现。由于这些不同点, Adapter和Bridge模式通常被用于软件生命周期的不同阶段。当你发现两个不兼容的类必须同时工作时,就有必要使用Adapter模式,其目的一般是为了避免代码重复。此处耦合不可预见。相反, Bridge的使用者必须事先知道:一个抽象将有多个实现部分,并且抽象和实现两者是独立演化的。Adapter模式在类已经设计好后实施;而Bridge模式在设计类之前实施。这并不意味着Adapter模式不如Bridge模式,只是因为它们针对了不同的问题。你可能认为facade是另外一组对象的适配器。但这种解释忽视了一个事实:即facade定义一个新的接口,而Adapter则复用一个原有的接口。记住,适配器使两个已有的接口协同工作,而不是定义一个全新的接口。
Composite模式和Decorator模式具有类似的结构图,这说明它们都基于递归组合来组织可变数目的对象。这一共同点可能会使你认为,Decorator对象是一个退化的Composite,但这一观点没有领会Decorator模式要点。相似点仅止于递归组合,同样,这是因为这两个模式的目的不同。Decorator 旨在使你能够不需要生成子类即可给对象添加职责。这就避免了静态实现所有功能组合,从而导致子类急剧增加。Composite则有不同的目的,它旨在构造类,使多个相关的对象能够以统一的方式处理,而多重对象可以被当作一个对象来处理。它重点不在于修饰,而在于表示。尽管它们的目的截然不同,但却具有互补性。因此Composite 和Decorator模式通常协同使用。在使用这两种模式进行设计时,我们无需定义新的类,仅需将一些对象插接在一起即可构建应用。这时系统中将会有一个抽象类,它有一些Composite子类和Decorator子类,还有
一些实现系统的基本构建模块。此时, composites 和decorator将拥有共同的接口。从Decorator模式的角度看,Composite是一个ConcreteComponet。而从Composite模式的角度看,Decorator则是一个leaf。当然,他们不一定要同时使用,正如我们所见,它们的目的有很大的差别。
另一种与Decorator模式结构相似的模式是Proxy这两种模式都描述了怎样为对象提供一定程度上的间接引用,proxy 和Decorator对象的实现部分都保留了指向另一个对象的指针,它们向这个对象发送请求。然而同样,它们具有不同的设计目的。像Decorator模式一样, Proxy 模式构成一个对象并为用户提供一致的接口。但与Decorator模式不同的是, Proxy模式不能动态地添加或分离性质,它也不是为递归组合而设
计的。它的目的是,当直接访问一个实体不方便或不符合需要时,为这个实体提供一个替代者,例如,实体在远程设备上,访问受到限制或者实体是持久存储的。在Proxy模式中,实体定义了关键功能,而Proxy 提供(或拒绝)对它的访问。在Decorator模式中,组件仅提供了部分功能,而一个或多个Decorator负责完成其他功能。Decorator模式适用于编译时不能(至少不方便)确定对象的全部功能的情况。这种开放性使
递归组合成为Decorator模式中一个必不可少的部分。而在Proxy模式中则不是这样,因为Proxy模式强调一种关系(Proxy与它的实体之间的关系),这种关系可以静态的表达。模式间的这些差异非常重要,因为它们针对了面向对象设计过程中一些特定的经常发生问题的解决方法。但这并不意味着这些模式不能结合使用。可以设想有一个Proxy - Decorator,它可以给Proxy添加功能,或是一个Proxy - Proxy用来修饰一个远程对象。尽管这种混合可能有用(我们手边还没有现成的例子),但它们可以分割成一些有用的模式。
行为模式的讨论
封装变化
封装变化是很多行为模式的主题。当一个程序的某个方面的特征经常发生改变时,这些模式就定义一个封装这个方面的对象。这样当该程序的其他部分依赖于这个方面时,它们都可以与此对象协作。这些模式通常定义一个抽象类来描述这些封装变化的对象,并且通常该模式依据这个对象来命名。例如,
• 一个Strategy对象封装一个算法
• 一个State对象封装一个与状态相关的行为
• 一个Mediator对象封装对象间的协议
这些模式描述了程序中很可能会改变的方面。大多数模式有两种对象:封装该方面特征的新对象,和使用这些新的对象的已有对象。如果不使用这些模式的话,通常这些新对象的功能就会变成这些已有对象的难以分割的一部分。例如,一个Strategy的代码可能会被嵌入到其Context类中,而一个State的代码可能会在该状态的Context类中直接实现。但不是所有的对象行为模式都象这样分割功能。例如, Chain of Responsibility)可以处理任意数目的对象(即一个链),而所有这些对象可能已经存在于系统中了。职责链说明了行为模式间的另一个不同点:并非所有的行为模式都定义类之间的静态通信关系。职责链提供在数目可变的对象间进行通信的机制。其他模式涉及到一些作为参数传递的对象。
对象作为参数
一些模式引入总是被用作参数的对象。例如Visitor。一个Visitor对象是一个多态的Accept操作的参数,这个操作作用于该Visitor对象访问的对象。虽然以前通常代替Visitor模式的方法是将Visitor代码分布在一些对象结构的类中,但Visitor从来都不是它所访问的对象的一部分。
其他模式定义一些可作为令牌到处传递的对象,这些对象将在稍后被调用。Command和Memento都属于这一类。在Command中,令牌代表一个请求;而在Memento中,它代表在一个对象在某个特定时刻的内部状态。在这两种情况下,令牌都可以有一个复杂的内部表示,但客户并不会意识到这一点。但这里还有一些区别:在Command模式中多态这个主题也贯穿于其他种类的模式。AbstractFactory,Builder( 3 . 2 )和Prototype都封装了关于对象是如何创建的信息。Decorator封装了可以被加入一个对象的职责。Bridge将一个抽象与它的实现分离,使它们可以各自独立的变化。很重要,因为执行Command对象是一个多态的操作。相反,Memento接口非常小,以至于备忘录只能作为一个值传递。因此它很可能根本不给它的客户提供任何多态操作。
Mediator和Observer是相互竞争的模式。它们之间的差别是, Observer通过引入Observer和Subject对象来分布通信,而Mediatorr对象则封装了其他对象间的通信。在Observer模式中,不存在封装一个约束的单个对象,而必须是由Observer和Subject对象相互协作来维护这个约束。通信模式由观察者和目标连接的方式决定:一个目标通常有多个观察者,并且有时一个目标的观察者也是另一个观察者的目标。Mediator模式的目的是集中而不是分布。它将维护一个约束的职责直接放在一个中介者中。
我们发现生成可复用的Observer和Subject比生成可复用的MMediator容易一些。Observer模式有利于Observer和Subject间的分割和松耦合,同时这将产生粒度更细,从而更易于复用的类。
另一方面,相对于Subject,Mediator中的通信流更容易理解。观察者和目标通常在它们被创建后很快即被连接起来,并且很难看出此后它们在程序中是如何连接的。如果你了解Observerr模式,你将知道观察者和目标间连接的方式是很重要的,并且你也知道寻找哪些连接。然而, Observer模式引入的间接性仍然会使得一个系统难以理解。
对发送者和接收者解耦
当合作的对象直接互相引用时,它们变得互相依赖,这可能会对一个系统的分层和重用性产生负面影响。命令、观察者、中介者,和职责链等模式都涉及如何对发送者和接收者解耦,但它们又各有不同的权衡考虑。
命令模式使用一个Command对象来定义一个发送者和一个接收者之间的绑定关系,从而支持解耦。
观察者模式通过定义一个接口来通知目标中发生的改变,从而将发送者(目标)与接收者(观察者)解耦。Observer定义了一个比Command更松的发送者-接收者绑定,因为一个目标可能有多个观察者,并且其数目可以在运行时变化,因此当对象间有数据依赖时,最好用观察者模式来对它们进行解耦。中介者模式让对象通过一个Mediator对象间接的互相引用,从而对它们解耦。因此各Colleague对象仅能通过Mediatorr接口相互交谈。因为这个接口是固定的,为增加灵活性Mediator可能不得不实现它自己的分发策略。可以用一定方式对请求编码并打包参数,使得Colleague对象可以请求的操作数目不限。中介者模式可以减少一个系统中的子类生成,因为它将通信行为集中到一个类中而不是将其分布在各个子类中。然而,特别的分发策略通常会降低类型安全性。最后,职责链模式通过沿一个潜在接收者链传递请求而将发送者与接收者解耦,因为发送者和接收者之间的接口是固定的,职责链可能也需要一个定制的分发策略。因此它与Mediator一样存在类型安全的问题。如果职责链已经是系统结构的一部分,同时在链上的多个对象中总有一个可以处理请求,那么职责链将是一个很好的将发送者和接收者解耦的方法。此外,因为链可以被简单的改变和扩展,从而该模式提供了更大的灵活性。
总结,除了少数例外情况,各个行为设计模式之间是相互补充和相互加强的关系。职责链可以使用Command模式将请求表示为对象。Interpreter可以使用State模式定义语法分析上下文。迭代器可以遍历一个聚合,而访问者可以对它的每一个元素进行一个操作。行为模式也与能其他模式很好地协同工作。例如,一个使用Composite模式的系统可以使用一个访问者对该复合的各成分进行一些操作。它可以使用职责链使得各成分可以通过它们的父类访问某些全局属性。它也可以使用Decorator对该复合的某些部分的这些属性进行改写。它可以使用Observer模式将一个对象结构与另一个对象结构联系起来,可以使用State模式使得一个构件在状态改变时可以改变自身的行为。复合本身可以使用Builder中的方法创建,并且它可以被系统中的其他部分当作一个Prototype。设计良好的面向对象式系统通常有多个模式镶嵌在其中,但其设计者却未必使用这些术语进行思考。然而,在模式级别而不是在类或对象级别上的进行系统组装可以使我们更方便地获取同等的协同性。
参考文献:
《Design Patterns》
《Java与模式》
《设计模式:可复用面向对象软件的基础》
注:转载请注明出处和参考文献(本文的原著),请遵守相关法律,仅供学习研究。不得用于商业目的。
《扁平时代的领导力》--周伟焜
(此文来自《华为人》第191期)2007年7月17日,应公司领导邀请,IBM大中华区董事长周伟焜先生莅临华为大学做了一场题为“扁平时代的领导力”的演讲。周伟焜先生以自己丰富的职业经历和对时代变迁的敏锐洞察力,深入浅出地分享了全球化进程中,公司管理者如何培养和发挥领导力来提高团队绩效、推动公司成长的理念和方法,值得探讨与借鉴。
各位下午好!
很高兴今天能有机会与大家交流“扁平时代的领导力”这个课题。
全球化是现在最热门的一个话题,相信大家都读过《世界是平的》这本书,如果你看完之后不感到害怕,那就是有点麻木。从过去几十年世界的变化中,我们就能体会到这个世界究竟是不是平的。当互联网泡沫破灭的时候,网络本身并没有产生衰退,因为互联网带来了很多公司,建设了很多宽带网络,因此把世界上很多的人都联系了起来,这给我们带来了新的机遇。作为电信业的提供者,华为也分享了这个机遇。随后,互联网、宽带把更多的工作进行重新分配。对于一个企业来讲,在这个平坦的世界里,我们是随之在不断改变的。以前,所谓的跨国企业是从总部输出思想、产品、做事方法,然后把它们出口到别的地方。随着竞争的加剧,这种国际化出口的模式慢慢转变为本地化模式,我们希望在每一个国家都有研究、开发、市场、产品和服务。但这个模式各自独立,所以在过去的十年里,我们开始全球化地整合在一起,不但是说所有的事情都由总部宣布,而且我们可以在全球范围内部署资源,用最恰当的成本来做事。
在全球化进程中,中国扮演着越来越重要的角色。中国市场经济的增长率、经济的总量、GDP的成长,使任何一家全球化企业都不可能不考虑来中国发展。这种情况下,中国的人才战已经开始了。我们在全球做了CEO调查,调查显示,员工的素质与敬业精神是企业发展的最关键的内部因素。对于企业变革而言,最大的障碍来自于管理变革的内部能力和领导力不足。12年前,我来到IBM中国公司时,我跟总部的领导说决定IBM公司在中国是否能成功,不是资金的问题,也不是市场的问题,而是人的问题。华为是中国在国际化道路上最成功的公司之一,再过三、五年,华为的规模会更大,可能在世界各个国家都有分公司,有研发,有生产,有销售,有服务,怎样有足够的人来管理这些公司?这是我很粗浅地看到的各位所面临的挑战。
IBM公司如果能熬到2011年,就是一百年的公司了。看一下历史,能熬了100年还能生存的公司,没有转去做其他行业,不是很多。我认为其中一个重要的原因是我们在最困难的时间里仍然能保留住最好的人才,大家一起去面对并解决问题。具体来讲,我们都做了哪些工作呢?我在这里与大家分享四个领域的内容:绩效管理、人才培养、组织气候、领导力。这四个领域在某个阶段都是最简单的事,但往往也是最难的事。
1、绩效管理
我认为绩效管理是现代企业的奠基石。绩效管理做得不好,其他的工作就会成为徒劳。绩效管理分为四个步骤。第一、设定目标及评量标准;第二、阶段性地回顾;第三、记录结果;第四、打分及评估。连接这四个步骤的纽带是及时反馈和沟通。在目标管理方面,经理们首先要写下评估期限内的业务目标,并确保目标符合公司的策略和价值观;其次要设立人力管理目标,反映你将怎样有效地领导员工,并创造一个让人才脱颖而出的管理氛围;然后还要设立发展目标,在评估期限内增强你实现业务目标和人力管理目标的能力。在这一系列的工作中,我认为最重要的是阶段式的回顾、反馈和沟通。因为如果目标定得不好,就会失之毫厘,谬以千里;如果目标定得好,但缺乏良好的沟通和反馈,目标没有得到良好的执行,就等于是没有目标。
2、人才培养
关于人才的培养,我们有同事概括为“三发”:发现人才、发展人才、发挥人才。你怎样用一些很好的办法看到一些好的人,去注意他们,去关怀他们,然后运用方法来发展他们,这是管理者很重要的责任。在我们的团队里,用到了这么一个例子:眼睛、鼻子、嘴巴、耳朵、手。
眼睛——观察员工看事情是否有远见,是否有预知能力,以及是否有把事情做好的能力。
鼻子——发掘员工的感知能力。为什么狮子不需要看到猎物但能捕捉到猎物,是因为它们的鼻子好,能嗅出猎物在哪里。
嘴巴和耳朵——培养员工双向沟通的能力。如果你看到一个与你共事的人,他一天到晚只讲不听,你应该想办法去帮助他。
手——执行的能力,也是最重要的能力。对于一个企业来讲,我认为战略与执行的作用是三七开。有些人很能讲,悟性很强,但不能去执行,这些人也是你的帮助对象。
如何发挥人才?我认为要给员工机会。当你将一个机会给一个你不是很放心的员工时,或者你把一个优秀的员工送到其他部门去发展时,可能会对你的部门产生风险,但是你创造了机会去发展人才和发挥人才。我认为一个成功的领导者,不要把焦点放在是否产生风险的问题上,更多是需要想办法来平衡这两件事。如果你很保守,永远不去冒这个风险,我相信好的员工一定不愿意跟你工作,这说明从领导力方面你有一定障碍。
3、组织气候
组织气候好像很抽象,但实际是存在的。据调查,一个公司的业绩有28%-36%是组织气候贡献的。
组织气候与领导的管理风格息息相关。管理风格有很多种,我列出了6种:专制型、权威型、关系型、民主型、领跑型、教练型。从我的经验来看,东方人的管理风格集中在专制型和领跑型。专制型领导以命令的方式让别人去做事情,作风明朗;领跑型的领导以身作则带领团队,看你做不了就自己卷起袖子来做。16年前我去做了IBM公司我自己的领导力分析,我也是这种风格的——为了不浪费时间,你不行了我自己来。我在过去的10多年里,很努力去调整我的管理风格。从领跑型到教练型,并不代表对各位一定有效,但从管理学者来讲,他们认为如果整个企业全是专制和领跑型的,对团队的细分,给员工的承诺,对员工的发展是有影响的。特别是领跑型的,员工们只是看你怎么做,最终可能没有机会真正学到本领。
评判一个团队的组织气候,不光是看大家在里面是否开心,更多的是要看这一个团队里面的透明度、责任、标准、承诺、员工对工作职责的理解是否清楚、员工是否有足够的灵活性去做他们想做的事、做得好的有没有奖励、做得不好的你知不知道、团队成员之间的协调与合作是否顺畅,等等。12年前我到IBM大中华区这个团队时就发现很多问题,但同事们通常都不跟我讲,后来我就花时间先把透明度、标准、责任提高,大概每隔一到两年我们就重新做一次,最后我们看到了结果,组织气候得到了很好的改善。
4、领导力
领导力方面,在新时代下,IBM要求领导者具备一系列的能力与素质,包括建立客户伙伴关系与拥抱挑战、协同合作、横向思维、明智决断、承担战略风险、赢得信任、促进成长和绩效、培育人才、发展社团、对未来充满热忱等。一个领导要做的事情,是要对在组织中所扮演的角色负责,要作为榜样,帮助公司改变。一个领导是不是好的领导者,核心的部分在于他的行为中有没有显示出公司的价值观,因为一家公司的价值观到最后并不是大家怎样讲,而是看他们领导的行为和他们做决定的方式和思维就可以知道了。
我认为对于跨国公司来讲,需要成功地对四种领导角色进行管理。业务主管要制定业务战略,合理分配资源,规避风险,实现全球规模的高效率和竞争力;国家和区域主管要与业务主管合作,根据区域特性制定区域战略,整合资源,贴近客户与市场、快速反应;职能主管要成为公司专业领域内的知识中心,发现并推动跨地区的经验积累与共享;总部主管要成为伯乐与教练,发掘和培养业务主管、区域主管、职能主管,并协调各个角色间的互动。
作为跨国公司,不管是IBM还是华为,我们面临的挑战都很大。我们要做的是在全球一盘棋的思想下,实行更高效率的、更有竞争力的管理,但同时还要考虑怎样才能在每一个国家、每一个地区有更灵活、更快速的反应。另外,怎么建立跨地区的经验分享与积累的能力,如何利用现有资源、规模、经验做到与贴近各地区客户/市场的创新和快速反映之间的平衡与最优化,也是全球化背景下领导者们所面临的课题。
总之,人才是最宝贵的资产,它决定着很多企业未来的成功。当我们谈到基业长青,其中最重要的一条是这家公司能不能把他的人才管理得更好。最后,祝愿华为公司基业长青,也希望IBM公司继续是各位最好的合作伙伴,跟大家一起迈进世界级领先企业之列。
Article from: http://blog.csdn.net/iammerryz/article/details/8743809
Data Mover
刀片存储(即“Blade”)常用称呼为Data Mover,主要功能是为用户提供文件级别的数据访问,操作系统叫DART,通过FC与后端存储矩阵连接,后端矩阵可以为Symmetrix和CLARiiON,同一系统允许多个Data Mover共存,Data Mover可以配置为主备模式,一台备用Data Mover最多可以做为7台主用Data Mover的备份。
由于Data Mover没有管理端口,因此必须和Control Station搭配使用,Control Station主要功能为管理Data Mover和辅助部分NAS功能,如:Failover、Replication等。Control Station使用红帽LINUX操作系统,同一系统最多允许二台Control Station互为备份。
最后上一张结构图,帮助大家理解。
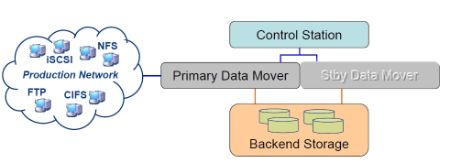
control station的操作系统是REHL,只负责管理和监控VNX-File的运行情况。Data Mover的操作系统是DART(EMC内部定制),负责数据和应用处理。
正常情况下,通过命令nas_version和Server_version看到的版本号是一样的,nas_version显示control station层面上的NAS版本号,server_version显示Data Mover层面上的NAS版本号。可是,当Data Mover在升级后被重启时,二个命令显示的操作系统版本可能不同。
nas_version查看到的是control station上的版本号,查看Data Mover的版本号可以通过命令server_version命令。Control station的操作系统安装在本地硬盘上,Data Mover的操作系统安装在后端存储的valut盘中。
[nasadmin@VNX5300 ~]$ nas_version
7.0.54-5
[nasadmin@VNX5300 ~]$ server_version ALL
server_2 : Product: EMC Celerra File Server Version: T7.0.54.5
server_3 : Product: EMC Celerra File Server Version: T7.0.54.5
从结果来看,貌似版本号是一样的。
只不过nas_version显示的版本应该是通过unisphere登陆到VNX上面显示的NAS的系统版本。
数字代表第几个Blade。
Blade2代表DataMover2,但是这不代表是第二个DataMover。因为DataMover最小的数字就是2,是从2开始计数。
你会很郁闷,那么Blade为什么没有1呢?
因为NAS可以有两个ControlStation(CS),分别是CS0和CS1。通常我们只会见到CS0,很少可以会配置两个CS。
Blade0是CS0
Blade1是CS1
Blade2是DataMover2
Blade3是DataMover3
由于设备型号的不同,设备所能连接DataMover的数量也是不同的。
Article from : http://my.oschina.net/u/437851/blog/348891